Abstract:
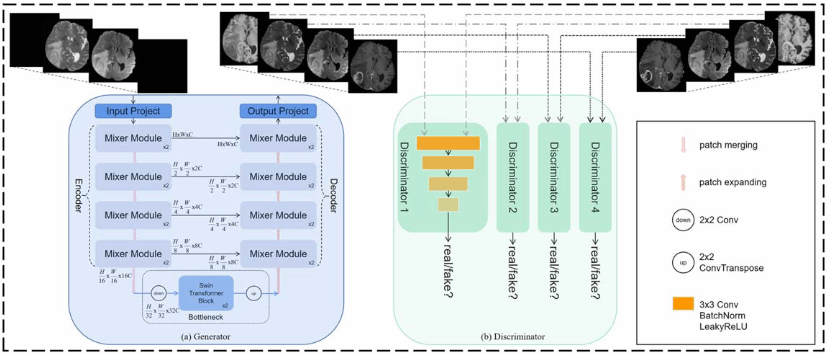
High-resolution multi-modal magnetic resonance imaging (MRI) is crucial in clinical practice for accurate diagnosis and treatment. However, challenges such as budget constraints, potential contrast agent deposition, and image corruption often limit the acquisition of multiple sequences from a single patient. Therefore, the development of novel methods to reconstruct under-sampled images and synthesize missing sequences is crucial for clinical and research applications.
Approach. In this paper, we propose a unified hybrid framework called SIFormer, which utilizes any available low-resolution MRI contrast configurations to complete super-resolution (SR) of poor-quality MR images and impute missing sequences simultaneously in one forward process. SIFormer consists of a hybrid generator and a convolution-based discriminator. The generator incorporates two key blocks. First, the dual branch attention block combines the long-range dependency building capability of the transformer with the high-frequency local information capture capability of the convolutional neural network in a channel-wise split manner. Second, we introduce a learnable gating adaptation multi-layer perception in the feed-forward block to optimize information transmission efficiently. Main results. Comparative evaluations against six state-of-the-art methods demonstrate that SIFormer achieves enhanced quantitative performance and produces more visually pleasing results for image SR and synthesis tasks across multiple datasets. Significance. Extensive experiments conducted on multi-center multi-contrast MRI datasets, including both healthy individuals and brain tumor patients, highlight the potential of our proposed method to serve as a valuable supplement to MRI sequence acquisition in clinical and research settings.
全文链接:DOI: 10.1088/1361-6560/acdc80
Abstract:
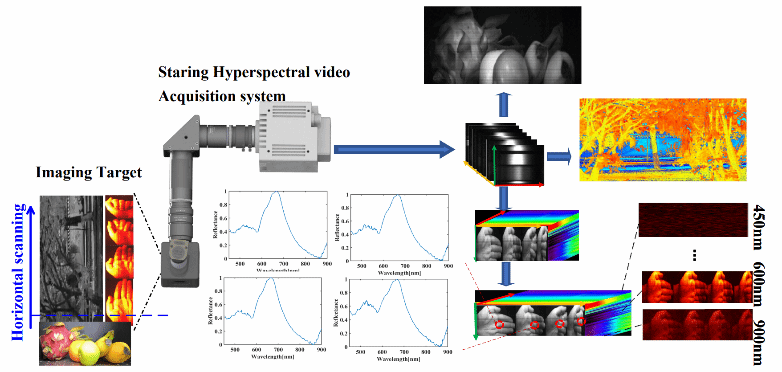
Hyperspectral imaging (HSI) combines spectroscopy and 2-D imaging to reveal sample composition and properties. Video level HSI helps to observe and analyze molecular features in dynamic processes. However, maintaining a high imaging speed will sacrifice spectral and spatial resolution. For real-time dynamic biological samples monitoring with high spectral and spatial resolution, this work proposes a novel HSI system, which includes a high-speed galvo mirror and a 10-Gb ethernet port CMOS sensor for spatial scanning and data acquisition. The galvo mirror can scan spatial light, accelerating the collection rate of hyperspectral cubes to the video level. The CMOS sensor can directly collect spectral spatial optical data at a speed of 1600 frames/s and synchronously outputs the data. Theoretically, this system can achieve N cubes/s with 624× (1600/ N ) ×500 resolutions, whose spectral bands and resolution are 500 and 3–5 nm, respectively. This is the first time hyperspectral data have been obtained at such a high throughput and cube rate. Chlorophyll sensing and mouse tumor localization were carried out to verify the system effectiveness. Hyperspectral videos of human palms both under stress and in a relaxed state, and hyperspectral videos of jellyfish navigation through water are recorded, considering the signal-to-noise ratio, the acquisition speed is reduced to one cube per second, and the acquisition cube size is expanded to 624×1600×500 . Then, spectral data are extracted from keyframes of the video to observe changes in molecular information. This promising tool offers great potential for living being detection.
全文链接:DOI: https://doi.org/10.1109/JSEN.2023.3308394
Abstract:
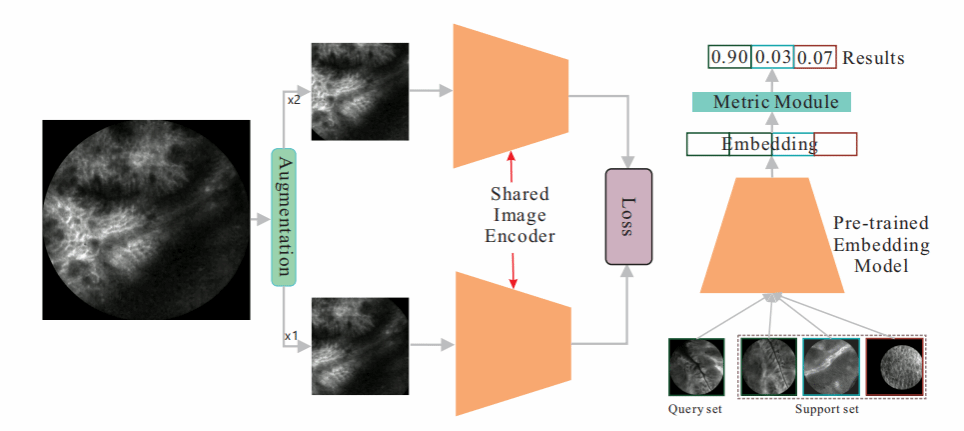
As an emerging early diagnostic technology for gastrointestinal diseases, confocal laser endomicroscopy lacks large-scale perfect annotated data, leading to a major challenge in learning discriminative semantic features. So, how should we learn representations without labels or a few labels? In this paper, we proposed a feature-level MixSiam method based on the traditional Siamese network that learns the discriminative features of probe-based confocal laser endomicroscopy (pCLE) images for gastrointestinal (GI) tumor classification. The proposed method is divided into two stages: self-supervised learning (SSL) and few-shot learning (FS). First, in the self-supervised learning stage, the novel feature-level-based feature mixing approach introduced more task-relevant information via regularization, facilitating the traditional Siamese structure can adapt to the large intra-class variance of the pCLE dataset. Then, in the few-shot learning stage, we adopted the pre-trained model obtained through self-supervised learning as the base learner in the few-shot learning pipeline, enabling the feature extractor to learn richer and more transferable visual representations for rapid generalization to other pCLE classification tasks when labeled data are limited. On two disjoint pCLE gastrointestinal image datasets, the proposed method is evaluated. With the linear evaluation protocol, feature-level MixSiam outperforms the baseline by 6% (Top-1) and the supervised model by 2% (Top1), which demonstrates the effectiveness of the proposed feature-level-based feature mixing method. Furthermore, the proposed method outperforms the previous baseline method for the few-shot classification task, which can help improve the classification of pCLE images lacking large-scale annotated data for different stages of tumor development.
全文链接:DOI: https://doi.org/10.1364/BOE.478832
Abstract:
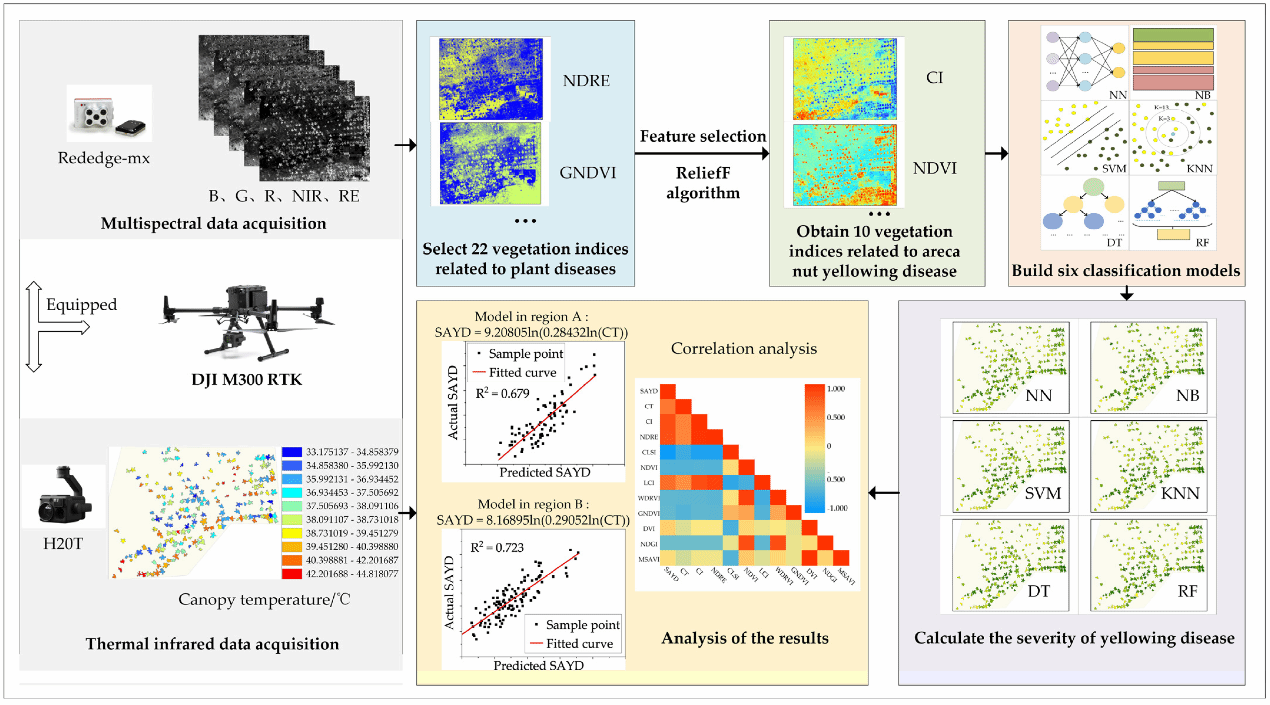
The areca nut is the primary economic source for some farmers in southeast Asia. However, the emergence of areca yellow leaf disease (YLD) has seriously reduced the annual production of areca nuts. There is an urgent need for an effective method to monitor the severity of areca yellow leaf disease (SAYD). This study selected an areca orchard with a high incidence of areca YLD as the study area. An unmanned aerial vehicle (UAV) was used to acquire multispectral and thermal infrared data from the experimental area. The ReliefF algorithm was selected as the feature selection algorithm and ten selected vegetation indices were used as the feature variables to build six machine-learning classification models. The experimental results showed that the combination of ReliefF and the Random Forest algorithm achieved the highest accuracy in the prediction of SAYD. Compared to manually annotated true values, the R2 value, root mean square error, and mean absolute percentage error reached 0.955, 0.049, and 1.958%, respectively. The Pearson correlation coefficient between SAYD and areca canopy temperature (CT) was 0.753 (p value < 0.001). The experimental region was partitioned, and a nonlinear fit was performed using CT versus SAYD. Cross-validation was performed on different regions, and the results showed that the R2 value between the predicted result of SAYD by the CT and actual value reached 0.723. This study proposes a high-precision SAYD prediction method and demonstrates the correlation between the CT and SAYD. The results and methods can also provide new research insights and technical tools for botanical researchers and areca practitioners, and have the potential to be extended to more plants.
全文链接:Doi: https://doi.org/10.3390/rs15123114








